The Project
Development of a grammar checking software for Punjabi, capable
of detecting various grammatical errors and providing suggestions to
correct those errors, if possible.
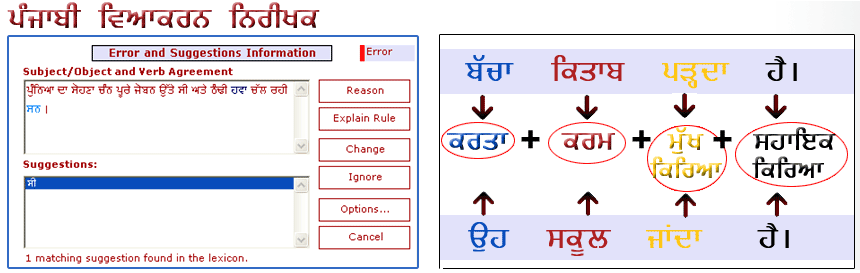
A grammar checker of
a language is a system that detects various grammatical errors in a given
text based on the grammar of that particular language, and reports those
errors to the user along with a list of helpful suggestions to rectify
those errors.
The input text will
be first given to a preprocessor, which will break the input text into
sentences and words. Then the tokenized text will be passed on to a
morphological analyzer, which will provide grammatical information for each
word in the given text. Then a POS tagger will perform part of speech
tagging. Then this POS tagged text will be passed on to a phrase chunker to
mark phrase and clause boundaries. Then in the last stage, syntax/agreement
checks will be performed based on the POS tag information at the phrase
level and then at the clause level. Any discrepancy found will be reported
to the user along with suggested corrections and detailed error
information.
Project Background
Grammar checking is
one of the widely used tools within language engineering. For the past few
years, commonly used word processors provide the grammar checkers for most
of the foreign languages. However, no such system is available for any of
the Indian languages. The use of computer is gaining popularity in the
day-to-day tasks of word processing, writing reports, and printing official
documents etc. Moreover, all these tasks demand text to be grammatically
correct. Therefore, a grammar checking system is the obvious requirement in
such a situation. Recently, Microsoft has released a Hindi version of its
popular word processing product, Microsoft Office. It is a commercial
product and details of the grammar checker in it (if any) will not be made
open. Therefore, to the best of our knowledge this work will be the first
of its kind for Indian languages, in general and Punjabi, in particular.
Indian languages have many things in common, so the present work could be
well extendable for other Indian languages too.
Objectives
- The
objectives of this research work include the following:
- To
adapt and enhance the existing morphological analysis and generation,
part of speech tagging, and phrase chunking systems
- To
develop the tools for parsing and error detection for compound and
complex sentences
- To
assemble these tools and develop a complete grammar checking system
for Punjabi language that will detect the maximum number of possible
errors and will provide suggestions for rectifying those errors,
wherever possible.
Applications
- This
system could be used with other information processing systems where
the input needs to be corrected grammatically before processing.
- Parts
of this system like morphological analyzer, morphological generator,
part of speech tagger, phrase chunker etc. could well be used at
various stages in machine translation systems, after making slight
modifications.
- This
system could be used for checking essays, formal reports, and letters
etc., written in Punjabi.
Second language learners can use this system as a language
aid to learn grammatical categories functioning in Punjabi sentences along
with grammatical structure of Punjabi.
- This
system as a whole can also be used as a post editor for various other
systems like machine translation system and optical character
recognition system for Punjabi.
- Technology
of this system could be used to develop grammar checking systems for
other languages sharing grammatical features with Punjabi.
Project Time-line
After 06 months
- Creating a corpus of ten thousand sentences for training and testing
- Adapting
the existing morphological analyzer and part of speech tagger
(developed by other NLP groups)
After 12 months
- Enhancing
phrasal or multiword expression database
- Enhancing
the performance of phrase chunker or shallow parser
- Digitizing
Punjabi grammar rules
- Developing
a parser for PUNJABI
After 18 months
- System
integration
- Continuing
the development of parser for PUNJABI
- Digitizing
new error rules to improve accuracy for simple sentences including
detection of some style errors
After 21 months
- Beta
version of the System
- Extending
the error coverage to compound and complex sentences
- Final
Testing and evaluation
Team Member
The project would be implemented by “Ministry of Communication &
Information Technology” (MC&IT) , New Delhi.
The Project Member at PUNJABI UNIVERSITY are:
Chief Investigator
Project Linguist
System Analyst
Lexical Entry Operator
- Miss. Mandeep Kaur
- Mr. Sandeep Malhotra
|